How to Architect Backend-to-Frontend Messaging for Second Brain
September 17, 2025
I'm building Second Brain, a voice AI assistant composed of multiple agents: the conversational agent you talk to, a backend "brain", and separate document and email tools. The flow is simple in prose: the user speaks, the backend "brain" processes the request and calls tools and databases. Responses can arrive as several messages: intermediate status updates, a final answer, and occasionally unsolicited notifications triggered by backend events ("That email just arrived").
Vercel serverless functions feel like the natural place to put that brain: deploy it and call it. But as you try this in the real world, three problems emerge immediately:
- Intermediate messages ("I'm searching your email for that PDF, hang on") need to get to the client while the brain continues to run.
- The brain can run longer than a single function invocation before finishing. If the function gets close to a timeout, how do you continue the work and still keep the client informed?
- A backend-initiated event occurs ("Hey - you just received that email you've been waiting for.") but there's no open HTTP connection available to send it to the user.
In this post I'll walk through the requirements, the tradeoffs, and a few practical architectures. I focus on architecture decisions: what should run where (Vercel, a realtime layer, queues, state stores) and how messages should be passed between the frontend, the backend brain, and realtime components.
Why this is harder than it sounds
Before we dive into solutions, it's helpful to be explicit about what the "brain" needs:
- Low-latency interactive path for intermediate messages.
- Reliable completion of long-running flows (or safe rehydration/retry).
- A way for backend-originated events to reach the user independently of the user opening a request.
- Per-user serialization/locking: the brain mustn’t run two conflicting instances for the same user concurrently.
- Multi-device support: a user might have multiple active tabs/devices, and the brain should be able to notify any or all of them.
If you sketch that out, you quickly see the mismatch with pure serverless HTTP functions: they are request→response. No persistent connection, no background processes.
Option 1 — Server-Sent Events (SSE)
SSE (Server-Sent Events) is a uni-directional, server→client streaming mechanism over HTTP. The client opens an EventSource, the server responds with Content-Type: text/event-stream and keeps the HTTP response open, sending framed events as lines like:
event: progress
id: 1
data: checking emailThe browser's EventSource API handles automatic reconnection and delivers those text events to your client. SSE is great for text-based server push, lightweight, and compatible with normal HTTP stacks (proxies, CDNs) that allow long-lived responses.
Important specifics for this post:
- SSE is uni-directional (server → client). If you need client→server realtime you still use normal HTTP/WebSocket requests.
- SSE streams text only (no binary). Large payloads should be encoded.
- Browsers auto-reconnect, which helps transient network issues, but you still need to design idempotency and replay if you care about missed events.
- In serverless environments, keeping a function invocation open to hold an SSE connection ties up the runtime and counts against invocation time and cost (and may hit platform limits). Edge/streaming runtimes can mitigate this but still have practical limits.
Pros:
- Very simple to implement on the client:
EventSourceis baked into browsers. - Works over regular HTTP and plays nicely with proxies.
Cons:
- Long-held connections defeat the serverless model: you’re tying up an invocation for potentially minutes (or hours) and paying for it.
- Not ideal for many concurrent clients (and not region-aware by default).
- SSE doesn't magically solve delivery when no client is connected. You must persist notifications and deliver them on reconnect, or provide a separate polling/notification mechanism.
If you have a handful of users and intermittent messages, SSE is perfectly fine. At scale, it's expensive and brittle unless you put the SSE connection onto a stateful service (containers, managed realtime providers).
// client.js
const es = new EventSource('/api/assistant/stream?session=abc');
es.onmessage = (e) => console.log('msg', e.data);
es.onerror = (err) => console.error('sse error', err);Server-side you must format lines according to the text/event-stream spec and keep the HTTP response open. Vercel's serverless functions aren't designed for long-lived connections, so for meaningful SSE you'll typically need either a streaming-capable edge runtime or to host the SSE endpoint on a service designed for long-lived connections.
Option 2 — A dedicated server that terminates a websocket
Run a persistent WebSocket endpoint (e.g. AWS API Gateway WebSocket, a fleet of containers behind an ALB/NLB, or a managed provider). The frontend holds a socket, backend pushes to those sockets. For the purposes of this option, treat it as a pure websocket solution: the frontend connects to a long-running websocket endpoint that the backend uses for all server→client realtime messages.
Pros:
- True duplex real-time channel. Great for intermediate messages and backend-initiated events.
- Lower-latency for push compared to repeatedly reinvoking serverless functions.
Cons:
- Not serverless on the connection layer — you must run and manage stateful infrastructure.
- Connection management (presence, reconnection, routing) and multi-region concerns are now your responsibility.
- If you move brain logic onto the websocket host, you may lose some of the convenience of your serverless platform.
This option keeps all realtime delivery on the websocket layer; Vercel can still host short-lived business logic, but any server-originated push goes through the websocket tier.
Option 3 — Streaming HTTP responses from Vercel functions
Modern platforms (including Vercel Edge Functions and many serverless runtimes) can stream responses via ReadableStream or chunked Transfer-Encoding. That solves intermediate messages for a single request: you can flush multiple partial responses over one HTTP call.
Pros:
- Simple to adopt for single client-initiated flows.
- Works well for token-by-token model outputs or status updates during a single invocation.
Cons:
- Still tied to the lifetime of the invocation; long processing still risks a timeout.
- Doesn't solve backend-initiated events (unless you're willing to keep a stream open forever, which returns you to the SSE/long-lived-connection problems).
// api/assistant/stream.js - Vercel Edge
export default async function handler(req) {
const { readable, writable } = new TransformStream();
const writer = writable.getWriter();
writer.write(encode('event: init\ndata: checking email\n\n'));
processInBackground(async (progress) => {
writer.write(encode(`event: progress\ndata: ${progress}\n\n`));
});
writer.write(encode('event: done\ndata: all good\n\n'));
writer.close();
return new Response(readable, { headers: { 'Content-Type': 'text/event-stream' } });
}That’s nice for one-off interactions but not a silver bullet.
What I actually implemented
The implementation keeps almost all brain logic in Vercel serverless functions while using a websocket as the realtime delivery channel for messages that cannot be handled synchronously.
Here's the overall setup:
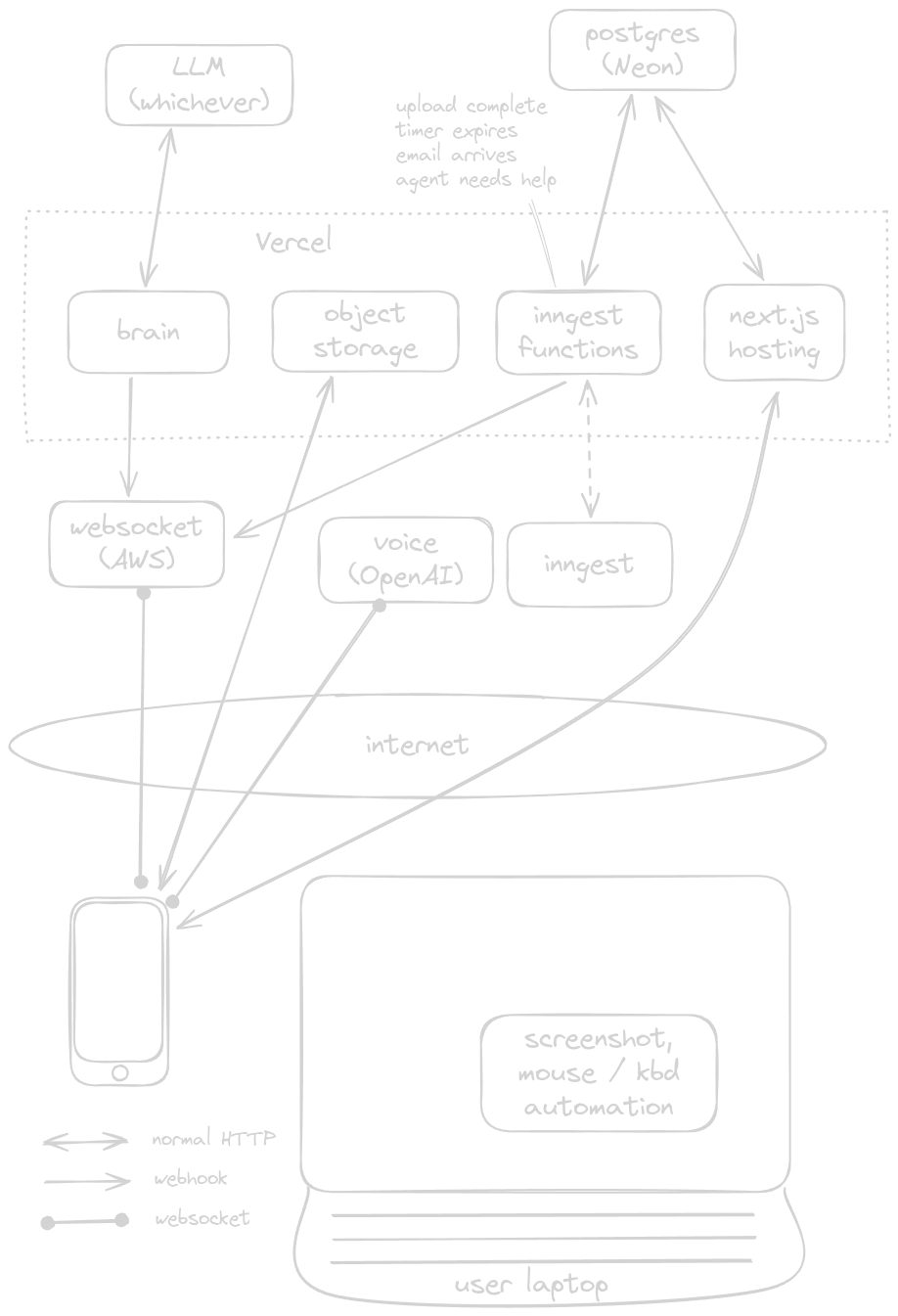
Key elements of the implementation
-
Front-to-back requests from the voice agent to the brain are standard HTTP requests. The frontend calls a secured route such as
/api/voiceToBrain. That route validates and authorizes the request and then invokes the brain entrypointbrainGo(). -
The
/api/voiceToBrainroute validates the request body (zod or similar) and callsbrainGo().brainGo()returns either a websocket message object ornull. If it returns a websocket message object and the request is in a mode that allows an immediate HTTP response,/api/voiceToBrainreturns that message in the HTTP response. IfbrainGo()returnsnull,/api/voiceToBrainreturns200and the voice agent expects the reply via the websocket. -
The frontend tool (
askBrain) handles both outcomes: if it receives an immediate message in the HTTP response it treats that as the result; if it receivesnullit returns a short explanatory message like "the brain is working, the response will arrive later" as the result of theaskBraincall so the voice agent knows that the call was successful but the result will arrive later. Note that this message is not spoken to the user, it is only given to the voice agent. -
brainGois the central server-side function that implements the brain logic. It acceptsuserIdandrecentContextand returns aPromise<Message | null>. Behavior:- Attempt to acquire the per-user lock. If lock acquisition fails, return
nullimmediately. This indicates that a brain is already running for that user. The users message will be recorded in the database though, so it will be processed when the current brain invocation is done. - Call
doOneBrainLoop(recentContext).doOneBrainLoopreturns{ needsAnotherLoop: boolean, websocketMessage?: Message }. - If
needsAnotherLoopis false and there is awebsocketMessage,brainGoreturns that message directly (this becomes the HTTP response when invoked via/api/voiceToBrain). - If
needsAnotherLoopis true and there's a message,brainGosends the message over the websocket (sendWebsocketMessage) and then continues into the next loop. - If
needsAnotherLoopis false and there's no message,brainGoreturnsnull. - If
needsAnotherLoopis true and there's no message,brainGoproceeds to the next loop. - The value of
needsAnotherLoopis primarily determined by whether the LLM calls thesayToUserAndContinuetool or thesayToUserAndQuittool. - If
brainGodetects it will run out of execution time and must continue later, it persists state and triggers the reinvocation path (brainToBrain) and then returnsnull.
- Attempt to acquire the per-user lock. If lock acquisition fails, return
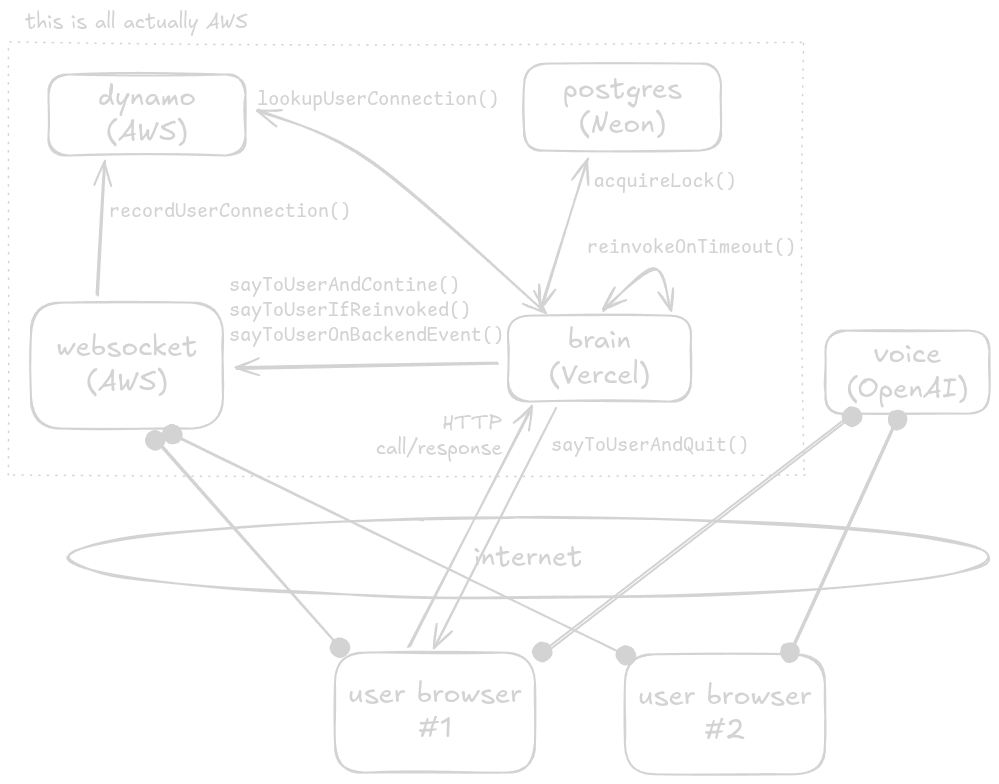
-
doOneBrainLoopacceptsrecentContextas an optional argument so the first loop can include the most recent client-side message (which may not yet be persisted). It fetches persisted messages and tool results as needed and composes the full context for LLM/tool calls. It returns whether another loop is required and an optionalwebsocketMessageto deliver now. -
Back-to-front messages have two delivery paths in the current architecture:
- Direct HTTP response: if
brainGois invoked directly by/api/voiceToBrainandbrainGodetermines it is finished and wants to send a final message, it returns that message via the HTTP response. This is the fastest path for immediate answers. - Websocket: for intermediate updates, background events, or when the brain reinvokes itself via
brainToBrain, messages are sent via the websocket. Breadcrumbs and backend event notifications always go down the websocket.
- Direct HTTP response: if
-
The voice interface has handlers for both delivery methods: it can accept an immediate HTTP response from
askBrainor listen to the websocket for system messages and breadcrumbs. The UI tracks websocket connection status and presence so it can surface delays or reconnections. -
Tools that send messages to the user include a
doneAfterThisflag. At low levels, tools indicate whether the message should be terminal (suitable for the HTTP path) or not (must be delivered via the websocket). This flag propagates up throughdoOneBrainLooptobrainGoso delivery decisions are deterministic. -
/api/brainToBrainis the reinvocation path: when the brain will exceed the current invocation it persists state and enqueues or reinvokes a Vercel function to continue processing (this is thereinvokeOnTimeout()function). In this reinvocation mode, returning messages via HTTP is not allowed — all messages must use the websocket. -
There is a websocket→brain HTTP route (kept for compatibility) which validates schema and auth but is effectively a no-op for client→brain messages in normal operation because front-to-back traffic flows over HTTP. This allows other messaging setups in the future, like sending user messages to the brain via the websocket.
Why this architecture is good
- Fast for the common path: user asks a question and receives a direct HTTP response within the same Vercel invocation when the brain can complete quickly.
- Supports intermediate messages, breadcrumbs, and backend events via the websocket for timely user feedback.
- Keeps brain logic within Vercel serverless functions for developer velocity and simple deployment.
- Preserves per-user locking and multi-device presence semantics so conflicting runs are avoided.
- Vercel handles all the deployment, global distribution, performance, etc, so I don't have to stand up and maintain all the containers and networking myself.
Why this architecture is bad
- Websocket-delivered replies can be slower due to extra network hops and reinvocation latency.
- It isn't "clean". Having two return paths feels wrong, like there must be some better way, but there's often a tension between architectureal cleanlieness and performance.
When the decision would be different
- If you have a tiny number of users: SSE or even polling is fine. Simpler, cheaper, faster to build.
- If you have strict latency and control needs and can invest in building and maintaining infrastructure: build a global websocket layer and move the brain into it.
- If you want to avoid infra entirely: use a managed realtime provider (Pusher/Ably/Stream/Firebase) — you still need some glue and performance would suffer but you avoid running connection servers.
- If you only need one-way notifications (server->client) and can accept some delay: mobile push notifications or email are also valid.
Conclusion
What I would do next if I had more time
If the product matures and the realtime load justifies it, I’d move to a globally distributed connection tier (containers + edge routing) and a small control-plane service that assigns brains to connections, persists state, and deals with reconnections. I’d keep the Vercel brain as a migration path and only move latency-critical parts out of it.
Or - hope that Vercel builds a websocket service and sprinkles their magic dust on it. I'd be user #1.
The Moral of the Story
The serverless model is amazing for a huge class of problems, but it’s intentionally constrained. When your app needs durable connections and background-initiated messages, accept that you’ll need a small amount of stateful infrastructure.
You can buy performance at the cost of complexity by moving more functionality into the stateful compute.